Introduction

Statistics
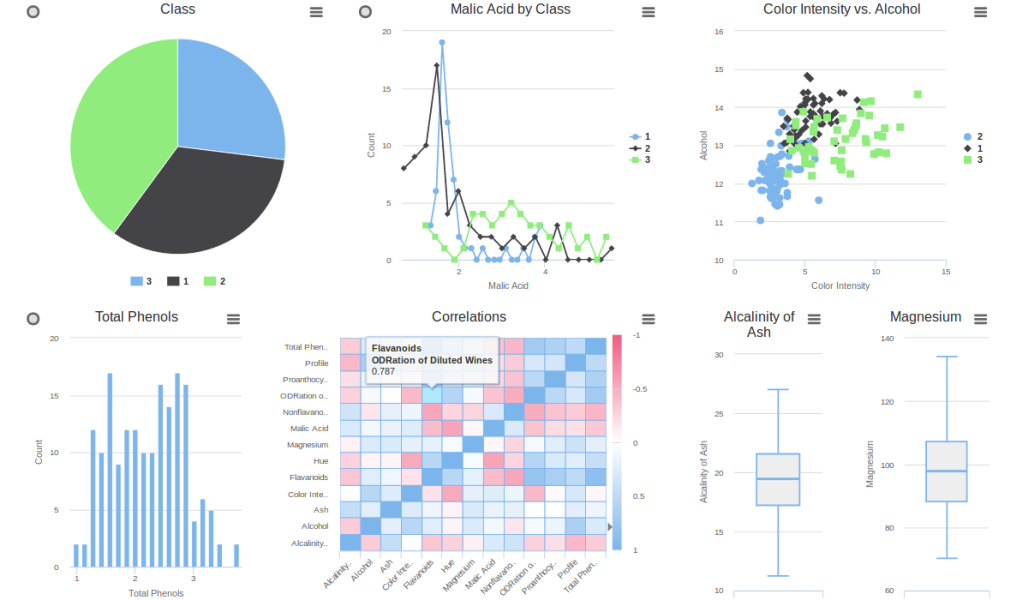
Ada allows users to conveniently explore and filter data, and calculate various statistics with embedded interactive visualizations, for instance, categorical and numerical distributions, scatters, correlations, and box plots.
Moreover, one of Ada's main functionalities is to produce dynamic and personalized
Data
Ada has been originally developed for NCER-PD project, for which it manages anonymize clinical data, biosample meta information provided by IBBL, and kinetic data from mPower mobile application and eGAIT shoe sensors.
Besides NCER-PD, the main instance of Ada currently harbours around 1300 data sets from diverse studies including DeNoPa, PPMI, TREND, GBA, ADNI, and mPower. Furthermore, Ada facilitates robust access control through LDAP authentication, and in-house user management with fine-grained permissions. With a convenient user management UI, admins can simply specify which data sets are a user allowed to access and which actions on the data set he/she is allowed to perform.
Metadata
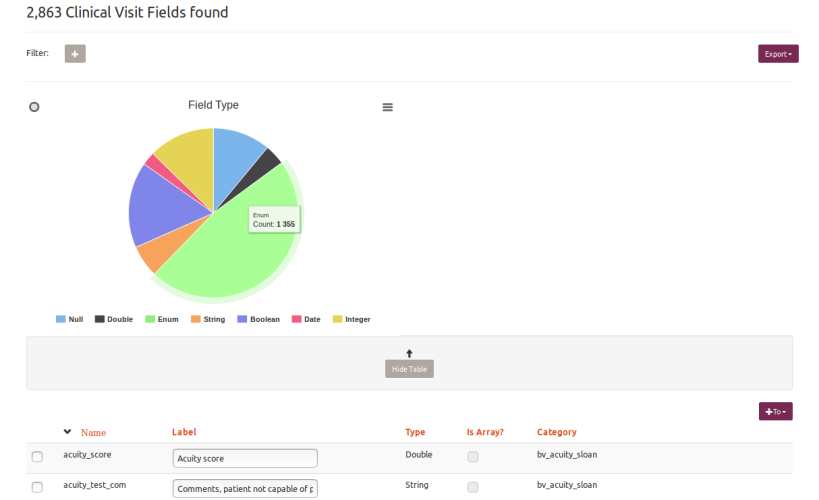
To define data set’s metadata Ada provides an editable dictionary, and a categorical tree with drag-and-drop manipulation.
Ada supports many data field types including number, date, boolean, enumeration, and json. These (collectively called
Import/Export
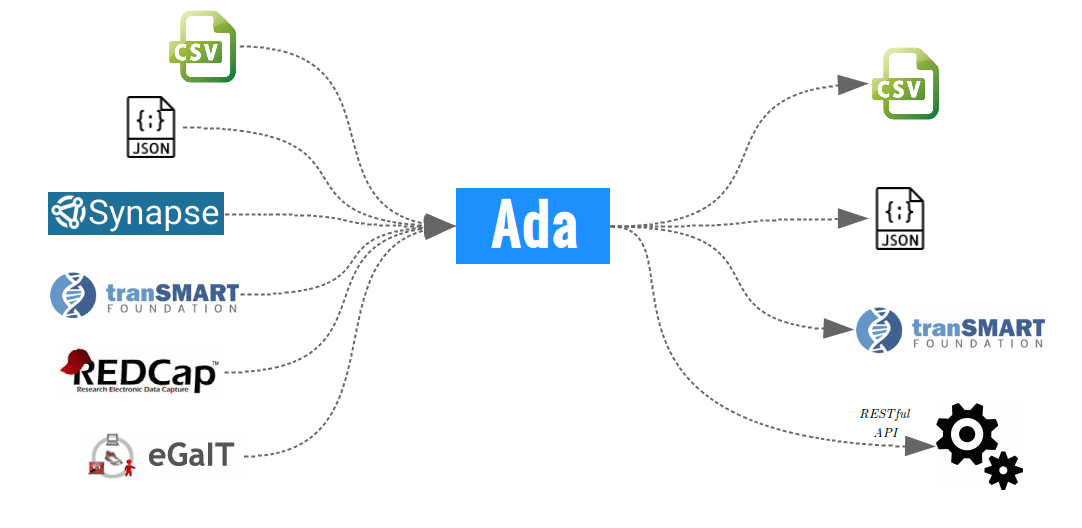
The data set import adapters currently support three file formats: CSV, JSON, and tranSMART data and mapping files, and three secured RESTful APIs: REDCap, Synapse, and eGait.
Any data sets provided from these sources can be added to (or removed from) Ada on-the-fly as well as scheduled for periodic execution. As such, Ada has potential to serve many translational medicine or any data exploration endeavors. For post-processing, filtered data can be exported into CSV, JSON, or tranSMART format.
Machine Learning
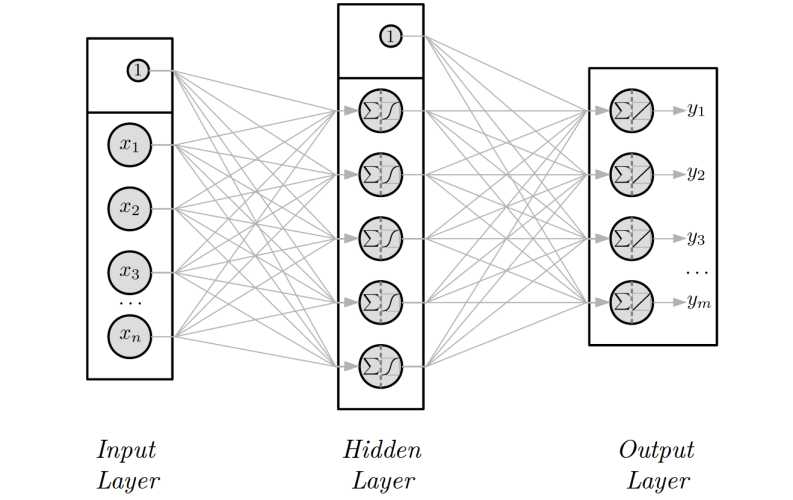
For more advanced analysis, well-grounded machine learning and statistical approaches were integrated using Spark ML library. This covers a wide variety of classification, regression, clusterization, feature selection, normalization, and time-series processing routines.
Ada is available for registered users only. If you wish to use Ada request an account.