Data Set Import
To create, edit, delete, schedule, or execute a data set import, go to Admin→Data Set Imports. Ada currently provides six data import adapters, three file-based: CSV, JSON, and tranSMART; and three RESTful-based: REDCap, Synapse, and eGaIT.
To create a new data set import, select a desired type in a drop down  located on the right side.
located on the right side.
If there is a data set import similar to the one you want to create, click  located on the right side
and select the source import in an autocomplete textbox. Then edit it accordingly.
located on the right side
and select the source import in an autocomplete textbox. Then edit it accordingly.
To execute a data set import click  at the associated row in the list table. Note that you do not need to wait for the import to fully proceed and meanwhile (as it is being executed) you can continue working at different sections of Ada.
Depending on the data set size an import might take several seconds to minutes to finish.
at the associated row in the list table. Note that you do not need to wait for the import to fully proceed and meanwhile (as it is being executed) you can continue working at different sections of Ada.
Depending on the data set size an import might take several seconds to minutes to finish.
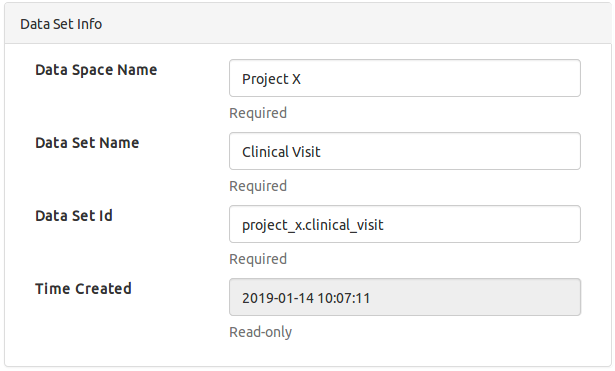
Data Set Info
This panel specifies the data set's identity info:
- Data space name usually corresponds to the study or project name and is manifested as a navigation tree node where a data set will be imported to.
- Data set name is the display name of a data set (can be changed later).
- Data set id is the unique data set identifier, which is automatically generated as
<data_space_name>.<data_set_name>but can be overridden if needed. This identifier cannot be changed once a data set is imported.
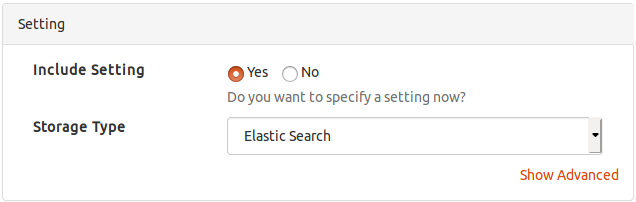
Setting
The technical setting of a data set containing, e.g., key field, default distribution field, and filter show style.
Note that this can (and most likely should) be changed after an import, so it is sufficient to specify only Storage Type (defaults to Elastic Search).
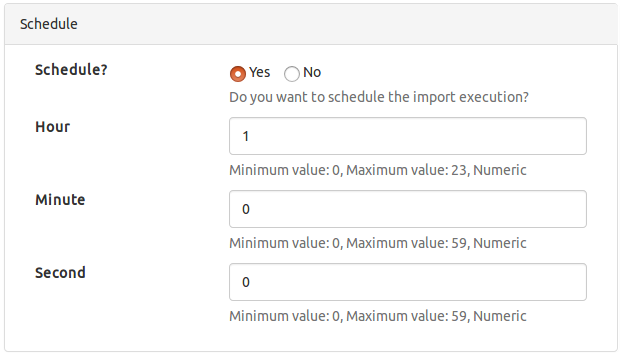
Schedule
Schedule defined by hour, minute, and second of the day, when a data set import should be periodically executed.
In the schedule example of the right an import is set to be executed every day at 1am. Note that if scheduling is desired Yes must be checked (defaults to No).
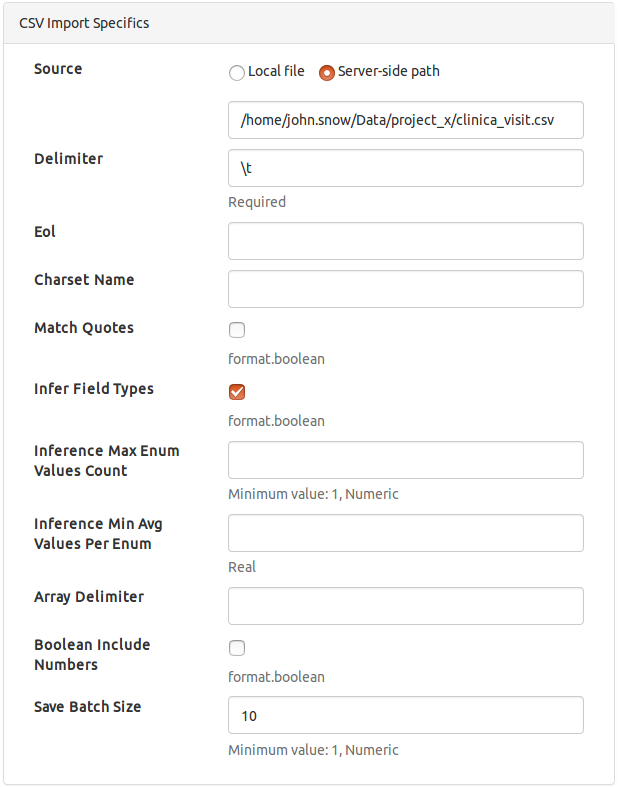
CSV
One of the most common file-based import types for a csv file specified as
- Source is either local (uploaded by an admin through the browser) or server-stored, in which case a path needs to be provided. Note that once a data set import is created a local file (if specified) is uploaded to the Ada server and the type is switched automatically to server-side.
- Delimiter defaults to comma (
,). For tab-delimited files enter\tas shown in the example. - EOL
- Charset Name
- Match Quotes
- Infer Field Types must be checked if field types are supposed to be inferred from the column values. Warning: if unchecked ALL fields/columns are considered to be Strings.
- Inference Max Enum Values Count defines the maximal number of distinct string values for which field enum type should be inferred. Defaults to
20. - Inference Min Avg Values per Enum defines the minimal allowed count per each distinct string value for which field enum type should be inferred. Defaults to
1.5. - Array Delimiter
- Boolean Include Numbers says (if checked) that fields/columns containing solely
0and1numeric values will be inferred as Booleans. - Save Batch Size
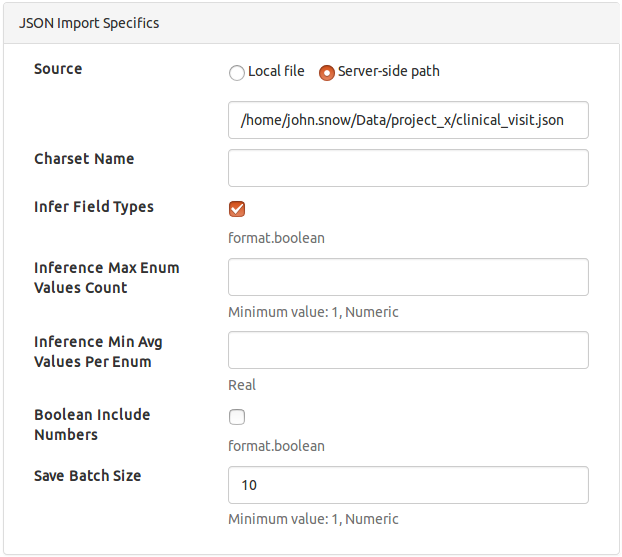
JSON
File-based import for a json file specified as
- Source
- Charset Name
- Infer Field Types
- Inference Max Enum Values Count
- Inference Min Avg Values per Enum
- Array Delimiter
- Boolean Include Numbers
- Save Batch Size
tranSMART
File-based import for tranSMART data and mapping files specified as
- Data Source
- Mapping Source
- Charset Name
- Match Quotes
- Infer Field Types
- Inference Max Enum Values Count
- Inference Min Avg Values per Enum
- Array Delimiter
- Boolean Include Numbers
- Save Batch Size
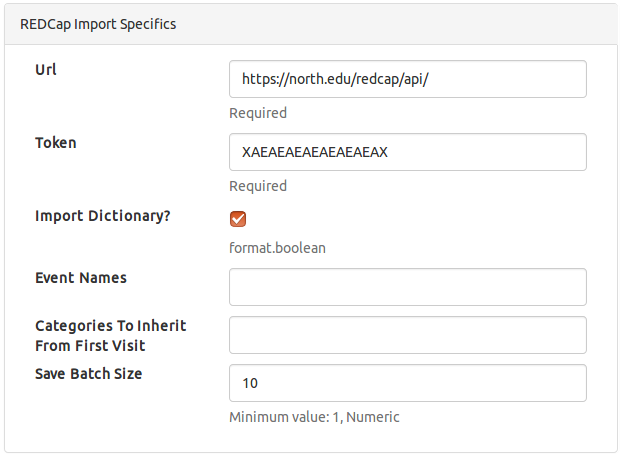
REDCap
RESTful-based import for a REDCap data capture system specified as
- URL
- Token
- Import Dictionary?
- Event Names
- Categories To Inherit From First Visit
- Save Batch Size
Synapse
RESTful-based import for Synapse, Sage Bionetworks's data provenance system, specified as
- Table Id
- Batch Size
- Download Column Files?
- Bulk Download Group Number
eGaIT
RESTful-based import for an eGaIT server storing shoe-sensor data specified as
- Import Raw Data